Changepoint Detection (CPD) refers to the problem of estimating the time at which the statistical properties of a time series… well… change. It originates in the 1950s, as a method used to automatically detect failures in industrial processes (quality control) and it is currently an active area of research that can boast of having a website on its own.
CPD is a generally interesting problem with lots of potential applications other than quality control, ranging from predicting anomalies in the electricity market (and, more generally, in financial markets) to detecting security attacks in a network system or even detecting electrical activity in the brain. The point is to have an algorithm that can automatically detect changes in the properties of the time series for us to make the appropriate decisions.
Whatever the application, the general framework is always the same: the underlying probability distribution function of the time series is assumed to change at one (or more) moments in time.
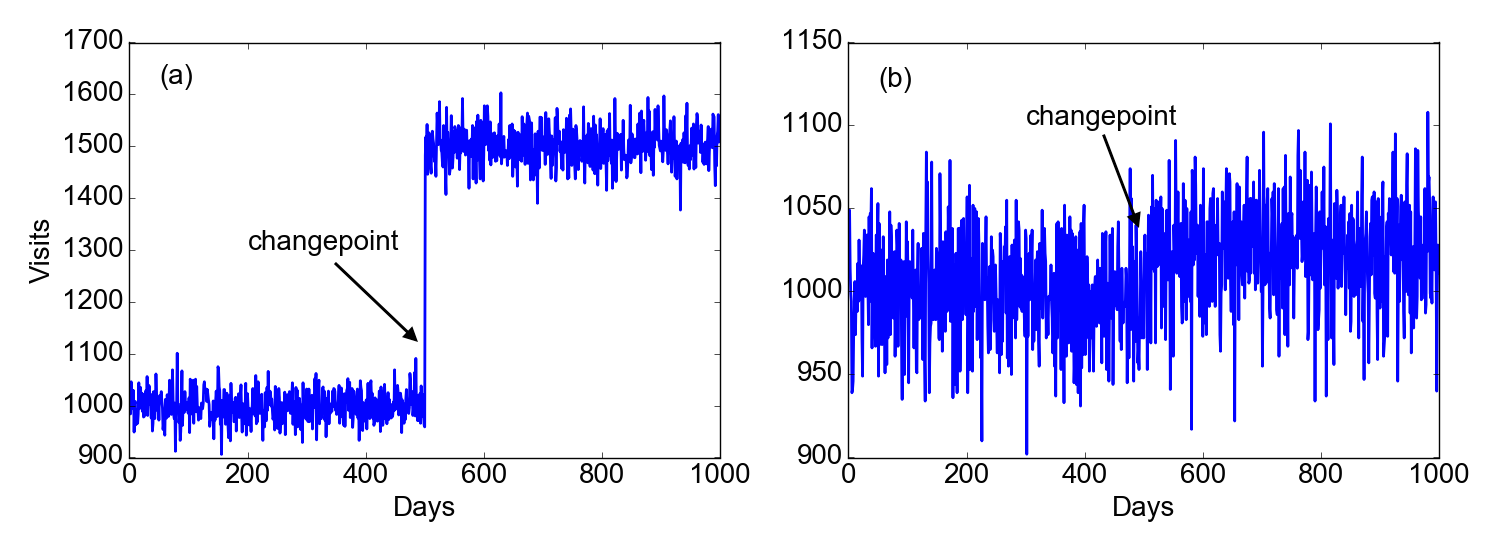
Figure 1 shows two examples of how this might work. Suppose we follow the history of visits on a website for 1000 days. In (a), we clearly see that at the 500th day something happens (maybe Google started indexing the website to the top of its search results). After that moment, the number of visits per day is clearly different. However, things are usually not as good as in this example… we may in fact be in the situation (b) of the figure. If I didn’t tell you that there is a changepoint at the 500th day, would you be able to find it?
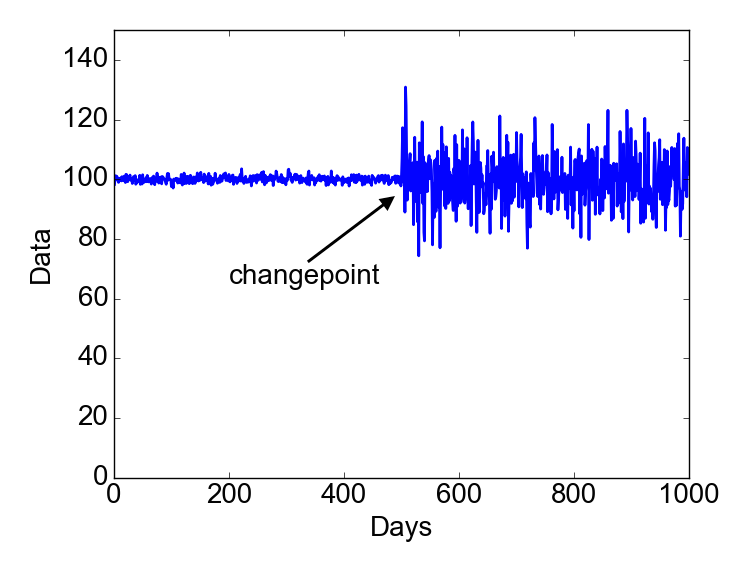
The cases above are examples in which the changepoint occurs because of a change in the mean. In other situations, a changepoint can occur because of a change in the variance, as in the figure below.
The idea of a CPD algorithm is to being able to automatically detect the positions of the most likely changepoints and, ideally, determine whether there is statistical evidence for claiming them to be “real”.
I will tackle this problem from a frequentist point of view, with the plan of talking about a bayesian approach in a future post.
As in all hypothesis testing problems, there is a potential issue of multiple testing. I have already talked about this issue. To avoid it, I will make the important assumption that the analysis involves a fixed sample so that we are going to perform one single hypothesis test. In other words the analysis is retrospective, as opposed to online sequential in which there is a stream of data that are continuously analyzed.
1. A frequentist solution.
In searching for an R package on CPD, I found $\texttt{changepoint}$ to be very well written and documented. There is a good paper in the Journal of Statistical Software that describes the package in more detail and can be freely accessed here.
In this post I will give my own interpretation on how to approach the problem, although mainly following the arguments and notation of the paper above and of this review.
First of all, for simplicity I will assume that there is a single changepoint during the whole time period, defined at the discrete times $t=1,2,3,\dots,N$. This case already captures the essence of CPD.
1.1 Model for a single changepoint
Let’s define $\tau$ as the changepoint time that we want to test. Each data point in the time series is assumed to be drawn from some probability distribution function (for example, it could be a binomial or a normal distribution). In this sense, the time series can be considered a realization of a stochastic process. The probability distribution function is assumed to be fully described by the quantity $\theta$ (in general, a set of parameters). For example, $\theta$ could be the probability $p$ of success in a binomial distribution, or the mean and variance in a normal distribution.
At this point the test goes like this: the null hypothesis is that there is no changepoint, while the alternative hypothesis assumes that there is a changepoint at the time $t=\tau$. More formally, here is our hypothesis test:
$$\begin{eqnarray}
H_0 &:& \theta_1=\theta_2=\dots=\theta_{N-1}=\theta_N \nonumber \\
H_1 &:& \theta_1=\theta_2=\dots=\theta_{\tau-1}=\theta_\tau\neq\theta_{\tau+1}=\theta_{\tau+2}=\dots=\theta_{N-1}=\theta_N \nonumber
\end{eqnarray}$$
The key in the expression $H_1$ above is in the inequality $\theta_\tau\neq\theta_{\tau+1}$: at some point in the time series, and precisely between $t=\tau$ and $t=\tau+1$, the underlying distribution changes.
The algorithm for detection is based on the log-likelihood ratio. Let’s first define what is the likelihood. The likelihood is nothing else than the probability of observing the data that we have (in the time series), assuming that the null (or the alternative) hypothesis are true. It is a measure of how good the hypothesis is: the highest the likelihood, the higher the data are well fit by the $H_0$ (or $H_1$) assumption.
Assuming independent random variables, under the null hypothesis $H_0$ the likelihood $\mathcal{L}(H_0)$ is given by the probability of observing the data $\mathbf{x}=x_1,\dots,x_N$ conditional on $H_0$. In other words,
$$\begin{equation}
\mathcal{L}(H_0)=p(\mathbf{x}|H_0)=\prod_{i=1}^{N}p(x_i|\theta_0)
\label{eq:L1}
\end{equation}$$
Let us define the likelihood of the alternative hypothesis,
$$\begin{equation}
\mathcal{L}(H_1)=p(\mathbf{x}|H_1)=\prod_{i=1}^{\tau}p(x_i|\theta_1)\prod_{j=\tau+1}^{N}p(x_j|\theta_2)
\label{eq:L2}
\end{equation}$$
The log-likelihood ratio $\mathcal{R}_\tau$ is then
$$\begin{equation}
\mathcal{R}_\tau=\log\left(\frac{\mathcal{L}_{H_1}}{\mathcal{L}_{H_0}}\right)=\sum_{i=1}^{\tau}\log p(x_i|\theta_1) + \sum_{j=\tau+1}^{N}\log p(x_j|\theta_2) - \sum_{k=1}^{N}\log p(x_k|\theta_0)
\label{eq:LRatio}
\end{equation}$$
Since $\tau$ is not known, the previous equation becomes a function of $\tau$. We can thus define a generalized log-likelihood ratio $G$, which is the maximum of $\mathcal{R}_\tau$ for all the possible values of $\tau$,
$$\begin{equation}
G = \max_{1\leq\tau\leq N}\mathcal{R}_\tau
\label{eq_likelihood}
\end{equation}$$
If the null hypothesis is rejected, then the maximum likelihood estimate of the changepoint is the value $\hat{\tau}$ that maximizes the generalized likelihood ratio,
$$\begin{equation}
\hat{\tau} = \underset{1\leq\tau\leq N}{\mathrm{argmax}} \ \mathcal{R}_\tau
\end{equation}$$
In general, the null hypothesis is rejected for a sufficiently large value of $G$. In other words, there is a critical value $\lambda^*$ such that $H_0$ is rejected if
$$\begin{equation}
\bbox[lightblue,5px,border:2px solid red]
{
2G=2R(\hat{\tau})>\lambda^*
}
\label{eq:criterion}
\end{equation}$$
The factor 2 is retained to be consistent with the $\texttt{changepoint}$ package.
The problem is how to define this critical value $\lambda^*$. The package $\texttt{changepoint}$ has several ways of defining the “penalty” factor $\lambda^*$. Going through the R code, I managed to find the definition of a few of them,
- BIC (Bayesian Information Criterion): $\lambda^* = k \log n$
- MBIC (Modified Bayesian Information Criterion): $\lambda^* = (k+1)\log n + \log(\tau) + \log(n-\tau+1)$
- AIC (Akaike Information Criterion): $\lambda^* = 2k$
- Hannan-Quinn: $\lambda^* = 2k\log(\log n)$
where $k$ is the number of extra parameters that are added as a result of defining a changepoint. For example, it is $k=1$ if there is just a shift in the mean or a shift in the variance.
At this point we are ready to look into a few more specific examples.
1.2 Normally distributed random variables - change in mean
Assume the variables that compose the time series are drawn from independent normal random distributions. We want to test the hypothesis that there is a change in the mean of the distribution at some discrete point in time $\tau$, while we assume that the variance $\sigma^2$ does not change. The probability density function is
$$\begin{equation} f(x|\mu,\sigma) = \frac{1}{\sqrt{2\pi\sigma^2}}\textrm{e}^{-(x-\mu)^2/2\sigma^2} \nonumber \end{equation}$$Let us call $\mu_1$ the mean before the changepoint, $\mu_2$ the mean after the changepoint and $\mu_0$ the global mean.
Under the null hypothesis there is no change in mean so the likelihood looks like
$$\begin{equation} \mathcal L_{H_0} = \frac{1}{\sqrt{2\pi\sigma^{2N}}}\prod_{i=1}^{N}\exp\left[-\frac{(x_i-\mu_0)^2}{2\sigma^2}\right] \label{eq:L3} \end{equation}$$Under the alternative hypothesis, a changepoint occurs at the time $\tau$ and the corresponding likelihood will then be
$$\begin{equation} \mathcal L_{H_1} = \frac{1}{\sqrt{2\pi \sigma^{2N}}}\prod_{i=1}^{\tau}\exp\left[-\frac{(x_i-\mu_1)^2}{2\sigma^2}\right] \prod_{j=\tau+1}^{N}\exp\left[-\frac{(x_j-\mu_2)^2}{2\sigma^2}\right]\ . \label{eq:L4} \end{equation}$$Okay, nothing really new so far. Equations (\ref{eq:L3}) and (\ref{eq:L4}) are in fact just specializations of eqs. (\ref{eq:L1}) and (\ref{eq:L2}) to the case of normally distributed random variables.
Now it is time to write the log-likelihood ratio, as in eq. (\ref{eq:LRatio}), obtaining
$$\begin{equation}
\bbox[white,5px,border:2px solid red]{
\mathcal{R}_\tau=\log\left(\frac{\mathcal{L}_{H_1}}{\mathcal{L}_{H_0}}\right)=-\frac{1}{2\sigma^2}\left[\sum_{i=1}^{\tau}(x_i-\mu_1)^2+\sum_{j=\tau+1}^{N}(x_j-\mu_2)^2-\sum_{k=1}^{N}(x_k-\mu_0)^2\right]
}
\label{eq:LR1}
\end{equation}$$
after which we should calculate $G$ and then apply the criterion (\ref{eq:criterion}).
1.3 Normally distributed random variables - change in variance
If there is a change in variance, rather than in mean, the analysis goes pretty similar to the previous section. Let us call $y_0$ and $\sigma_0^2$ the global mean and variance, respectively. Under the null hypothesis, the likelihood is
$$\begin{equation} \mathcal L_{H_0} = \frac{1}{\sqrt{2\pi\sigma_0^{2N}}}\prod_{i=1}^{N}\exp\left[-\frac{(x_i-\mu_0)^2}{2\sigma_0^2}\right] \nonumber \end{equation}$$and under the alternative hypothesis,
$$\begin{equation}
\mathcal L_{H_1} = \frac{1}{\sqrt{2\pi\sigma_1^{2\tau}\sigma_2^{2(N-\tau)}}}\prod_{i=1}^{\tau}\exp\left[-\frac{(x_i-\mu_0)^2}{2\sigma_1^2}\right]
\prod_{j=\tau+1}^{N}\exp\left[-\frac{(x_j-\mu_0)^2}{2\sigma_2^2}\right]\ .
\nonumber
\end{equation}$$
The log-likelihood ratio is somewhat more complicated than before,
$$\begin{eqnarray}
\mathcal{R}_\tau=\log\left(\frac{\mathcal{L}_{H_1}}{\mathcal{L}_{H_0}}\right)= & N\log\sigma_0-\tau\log\sigma_1-(N-\tau)\log\sigma_2 \nonumber \\ & + \sum_{k=1}^{N}\frac{(x_k-\mu_0)^2}{2\sigma_0^2}-\sum_{i=1}^{\tau}\frac{(x_i-\mu_0)^2}{2\sigma_1^2}-\sum_{j=\tau+1}^{N}\frac{(x_j-\mu_0)^2}{2\sigma_2^2}
\label{eq:Rvar1}
\end{eqnarray}$$
However, noting that $\sum_{k=1}^N(x_k-\mu_0)^2=N\sigma_0^2$, $\sum_{i=1}^\tau(x_i-\mu_0)^2=\tau\sigma_1^2$ and $\sum_{j=\tau+1}^N(x_j-\mu_0)^2=(N-\tau)\sigma_2^2$ the three last terms in eq. (\ref{eq:Rvar1}) cancel out. The final expression for $R_\tau$ is then
1.4 Bernoulli distributed random variables - change in mean
The Bernoulli distribution is possibly the easiest distribution of all. It models binary events that have probability $p$ of happening and probability $1-p$ of not happening. This is why it is usually introduced in probability theory with the “coin flipping” example.
As before, we can write the likelihood under the null hypothesis
$$\begin{equation} \mathcal L_{H_0} = p_0^m(1-p_0)^{N-m} \end{equation}$$and under the alternative hypothesis,
$$\begin{equation}
\mathcal L_{H_1} = p_1^{m_1}(1-p_1)^{\tau-m_1}p_2^{m_2}(1-p_2)^{N-\tau-m_2} .
\end{equation}$$
The log-likelihood ratio becomes
$$\bbox[white,5px,border:2px solid red]{ \begin{eqnarray} \mathcal{R}_\tau=\log\left(\frac{\mathcal{L}_{H_1}}{\mathcal{L}_{H_0}}\right) = & \hspace{-2cm} m_1\log(p_1) + (\tau-m_1)\log(1-p_1) + m_2\log(p_2) \nonumber \\ & + (N-\tau-m_2)\log(1-p_2) - m\log p_0 - (N-m)\log(1-p_0) \hspace{1.5cm} \label{eq:LR3} \end{eqnarray} }$$1.5 Poisson distributed random variables - change in mean
Here we assume that the random variables follow a Poisson distribution,
$$\begin{equation}
f(x|\lambda) = \frac{\lambda^x \textrm{e}^{-\lambda}}{x!}, \ \ x\in \mathbb{N}
\nonumber
\end{equation}$$
where $x$ represents the number of events during a pre-defined time interval and $\lambda$ the expected number of events during the same time interval.
As before, we can write the likelihood under the null hypothesis
$$\begin{equation} \mathcal L_{H_0} = \prod_{i=1}^N\frac{\lambda_0^{x_i} \textrm{e}^{-\lambda_0}}{x_i!} \end{equation}$$and under the alternative hypothesis,
$$\begin{equation}
\mathcal L_{H_1} = \prod_{i=1}^{\tau}\frac{\lambda_1^{x_i} \textrm{e}^{-\lambda_1}}{x_i!}
\prod_{j=\tau+1}^{N}\frac{\lambda_2^{x_j} \textrm{e}^{-\lambda_2}}{x_j!}
\end{equation}$$
and the log-likelihood ratio,
$$\begin{equation}
\mathcal{R}_\tau=\log\left(\frac{\mathcal{L}_{H_1}}{\mathcal{L}_{H_0}}\right) = \sum_{i=1}^{\tau}\log\left(\frac{\lambda_1^{x_i}\mathrm{e}^{-\lambda_1}}{x_i!}\right)
+ \sum_{j=\tau+1}^{N}\log\left(\frac{\lambda_2^{x_j}\mathrm{e}^{-\lambda_2}}{x_j!}\right)
- \sum_{k=1}^{N}\log\left(\frac{\lambda_0^{x_k}\mathrm{e}^{-\lambda_0}}{x_k!}\right) .
\nonumber
\end{equation}$$
Noting that $N\lambda_0 = \tau\lambda_1 + (N-\tau-1)\lambda_2$, the latter expression can be greatly simplified to give
$$\begin{equation}
\bbox[white,5px,border:2px solid red]{
\mathcal{R}_\tau=\log\left(\frac{\mathcal{L}_{H_1}}{\mathcal{L}_{H_0}}\right) = m_1\log\lambda_1
+ m_2\log\lambda_2 - m_0\log\lambda_0
}
\label{eq:LR4}
\end{equation}$$
where $m_1=\sum_{i=1}^{\tau}x_i$, $m_2=\sum_{j=\tau+1}^{N}x_j$ and $m_0=\sum_{i=1}^{N}x_k$.
2. Applications
We are finally in a position to test the criteria of above for different potential applications. Below I am listing a series of problems with the “solution” underneath. The solution is based on a code that I have written in Python that you can find here,
The code is not optimized, the purpose of it is to show that the methods described above work well at finding single changepoints in time series. The criterion for rejecting (or not) the null is the Bayes Information Criterion (BIC). Feel free to use other criteria.
2.1 Problem 1. Normal distribution: change in mean.
Problem definition: A website receives a certain amount of visits per day. Lately, the marketing team has worked on improving the position of the website on Google searches (Search Engine Optimization). We want to test if this has resulted in an increase in visits on the website.
2.1.1 Parameters of problem 1
Note: these parameters are completely made up. You can change the parameters in the code as you wish, also making the test fail (not rejecting the null),
- Probability density distribution $p\sim \exp[(x-\mu)^2/2\sigma^2]$
- $\sigma=50$
- $\mu = 1000 \ \ \mathrm{for} \ \ \tau\leq 2500; \mu = 1020 \ \ \mathrm{for} \ \ \tau>2500$
2.1.2 Solution
In IPython, run:1
2
3
4
5
6
7
8
9
10
11
12
13In [1]: run changepoint.py
In [2]: d = cpt(type="normal-mean")
In [3]: d.plot_data()
In [4]: d.find_changepoint()
---------------------
2G = 1.019912e+06
sigma**2*lambda = 4.406242e+04
H0 rejected
Changepoint detected at position: 2471
m1 = 1000.217251
m2 = 1020.416748
---------------------
In [5]: d.plot_score()
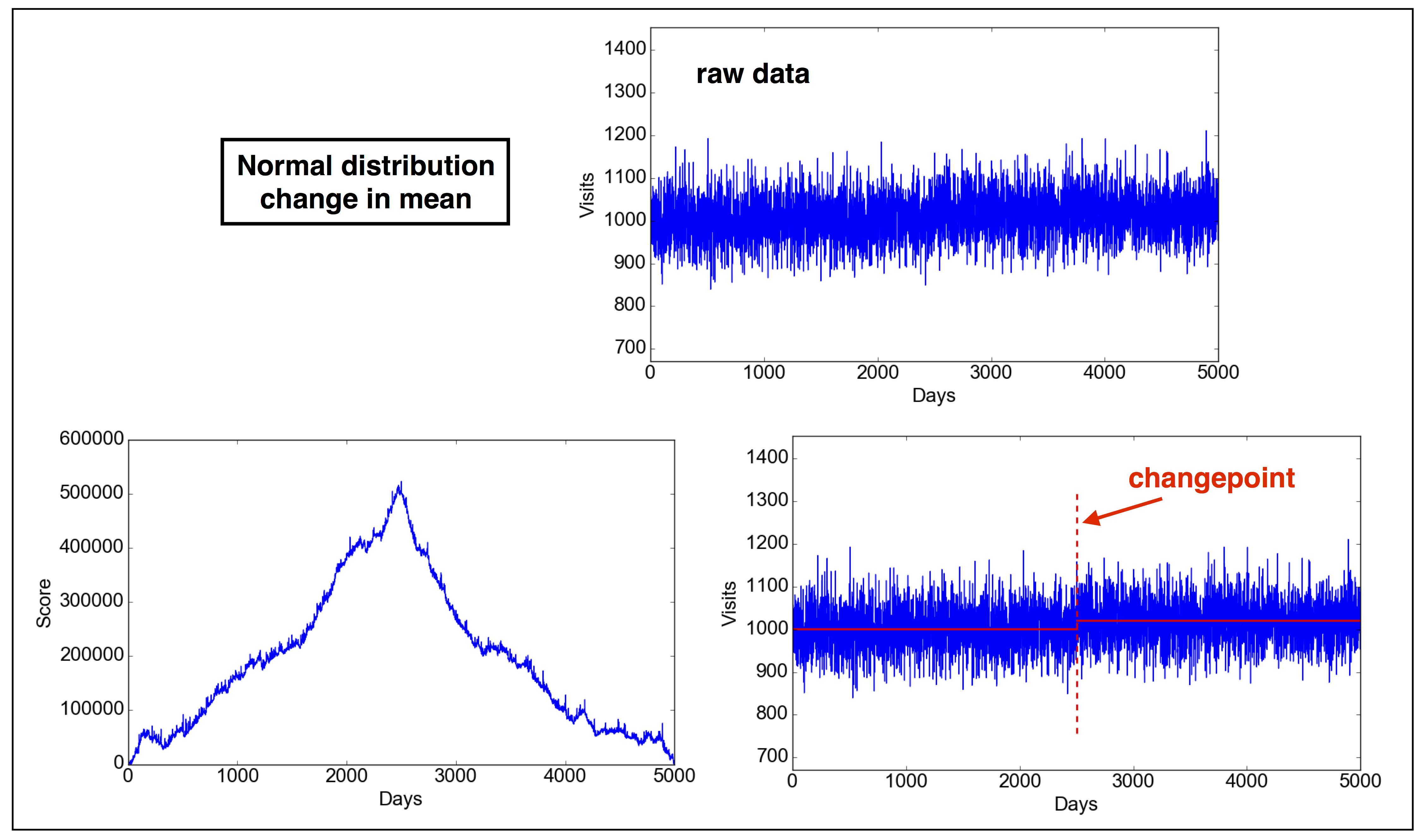
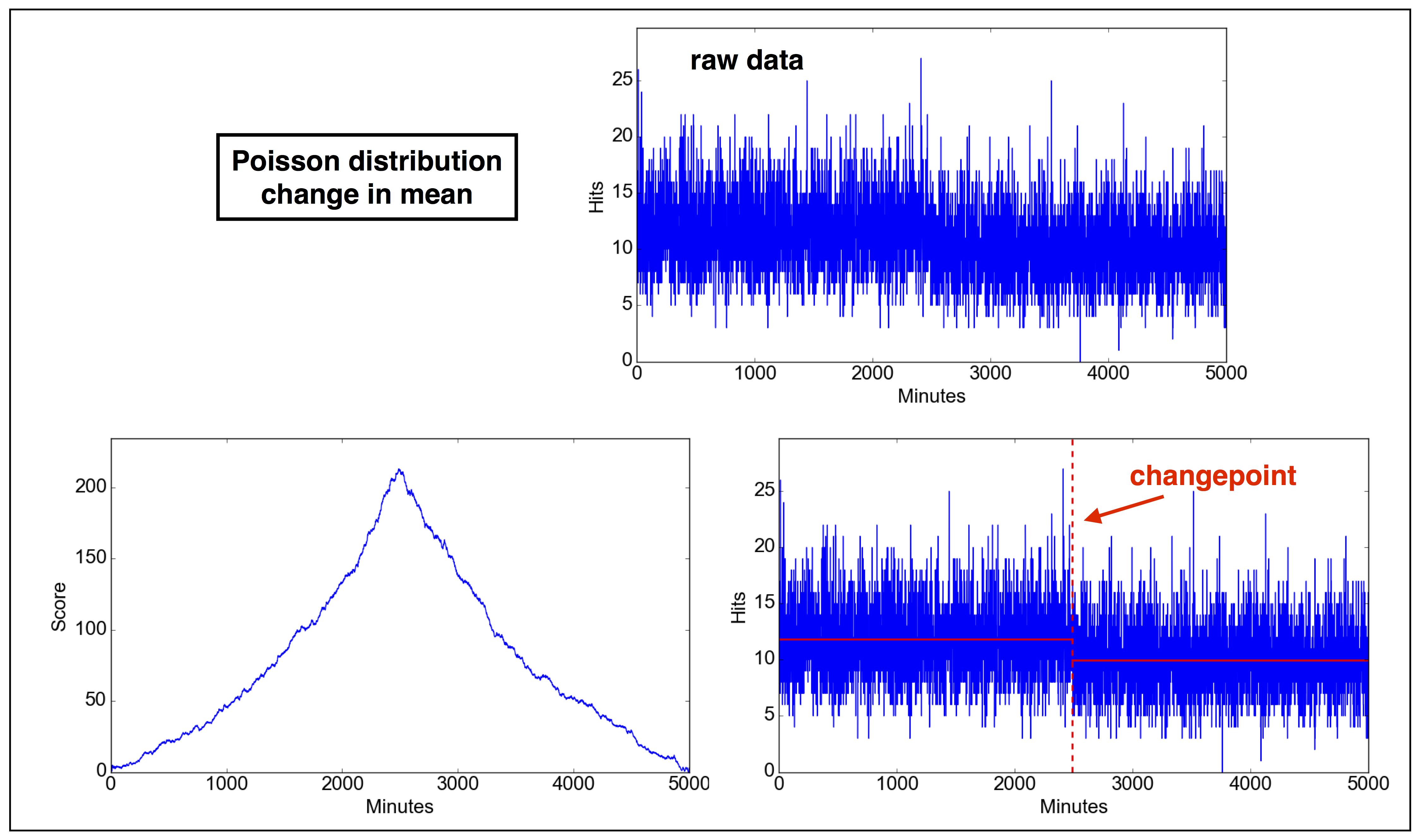
2.2 Problem 2. Normal distribution: change in variance.
Problem definition: Many economists and investors are interested in understanding why financial markets can show abrupt changes in volatility. Assume that such a change in volatility happens in the dataset we are provided. We need to detect when this change happens in the dataset in order to improve our investment model.
2.2.1 Parameters of problem 2
Note: these parameters are completely made up. You can change the parameters in the code as you wish, also making the test fail (not rejecting the null),
- Probability density distribution $p\sim \exp[(x-\mu)^2/2\sigma^2]$
- $\mu=1000$
- $\sigma= 10 \ \ \mathrm{for} \ \ \tau\leq 2500; \sigma = 20 \ \ \mathrm{for} \ \ \tau>2500$
2.2.2 Solution
In IPython, run:1
2
3
4
5
6
7
8
9
10
11
12
13In [1]: run changepoint.py
In [2]: d = cpt(type="normal-var")
In [3]: d.plot_data()
In [4]: d.find_changepoint()
---------------------
2G = 1.120977e+03
sigma**2*lambda = 1.703439e+01
H0 rejected
Changepoint detected at position: 2503
std1 = 9.943208
std2 = 19.903438
---------------------
In [5]: d.plot_score()
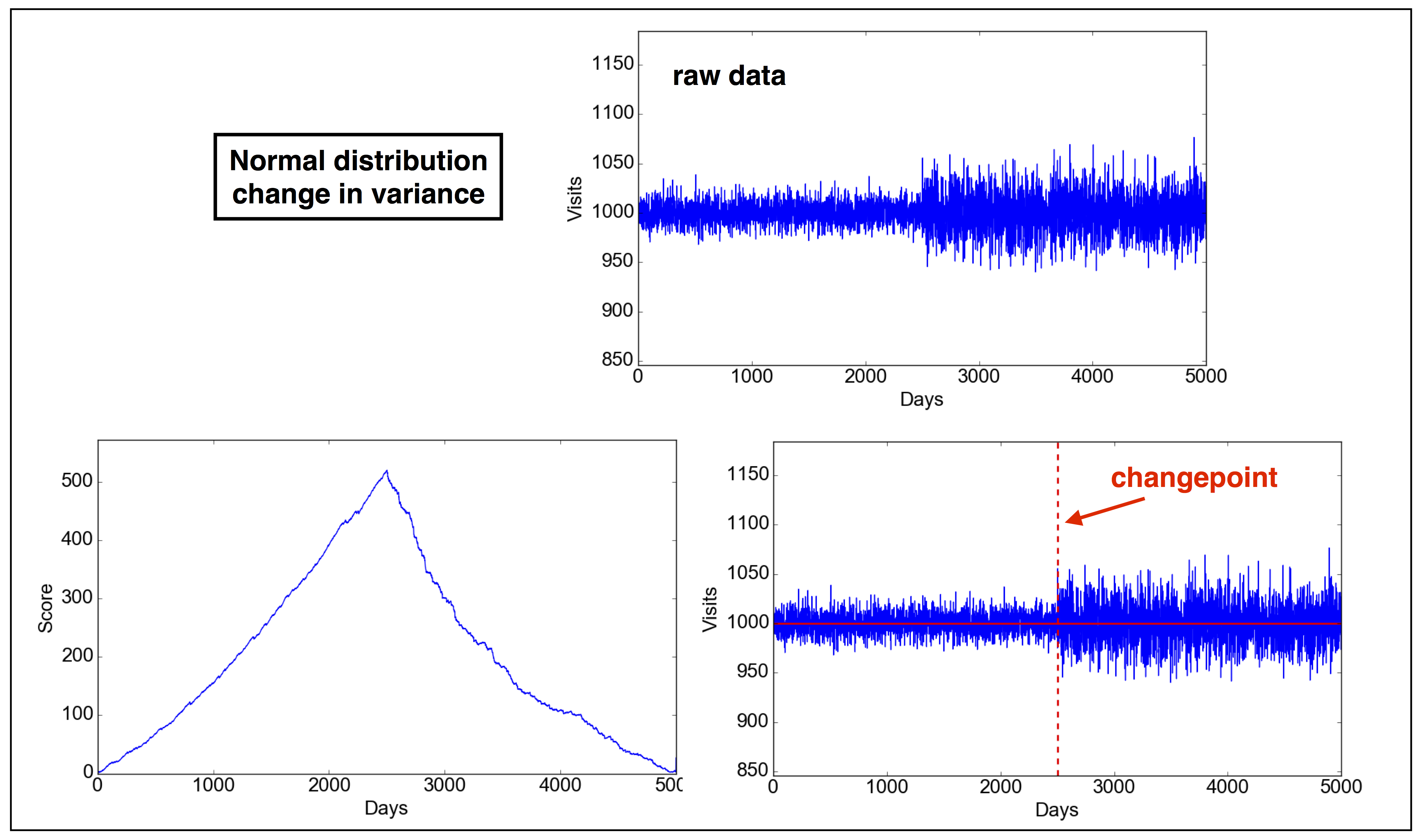
2.3 Problem 3. Bernoulli distribution: change in mean.
Problem definition: An industrial chain delivers products that need to be manually inspected. Under normal circumstances, about 10% of the products are found with small imperfections that need to taken care of. Recently, a potential bug in the software has been found which may have caused an increase in the inspection failure rate. We want to detect when the bug was introduced and whether the failure rate has increased because of it.
2.3.1 Parameters of problem 3
Note: these parameters are completely made up. You can change the parameters in the code as you wish, also making the test fail (not rejecting the null),
- Probability density distribution: inspection fails with probability $p$, does not fail with probability $1-p$
- $p = 0.10 \ \ \mathrm{for} \ \ \tau\leq 2500; p = 0.15 \ \ \mathrm{for} \ \ \tau>2500$
2.3.2 Solution
In IPython, run:1
2
3
4
5
6
7
8
9
10
11
12
13In [1]: run changepoint.py
In [2]: d = cpt(type="bernoulli-mean")
In [3]: d.plot_data()
In [4]: d.find_changepoint()
---------------------
2G = 4.008289e+01
sigma**2*lambda = 1.703439e+01
H0 rejected
Changepoint detected at position: 2587
m1 = 0.093931
m2 = 0.152507
---------------------
In [5]: d.plot_score()
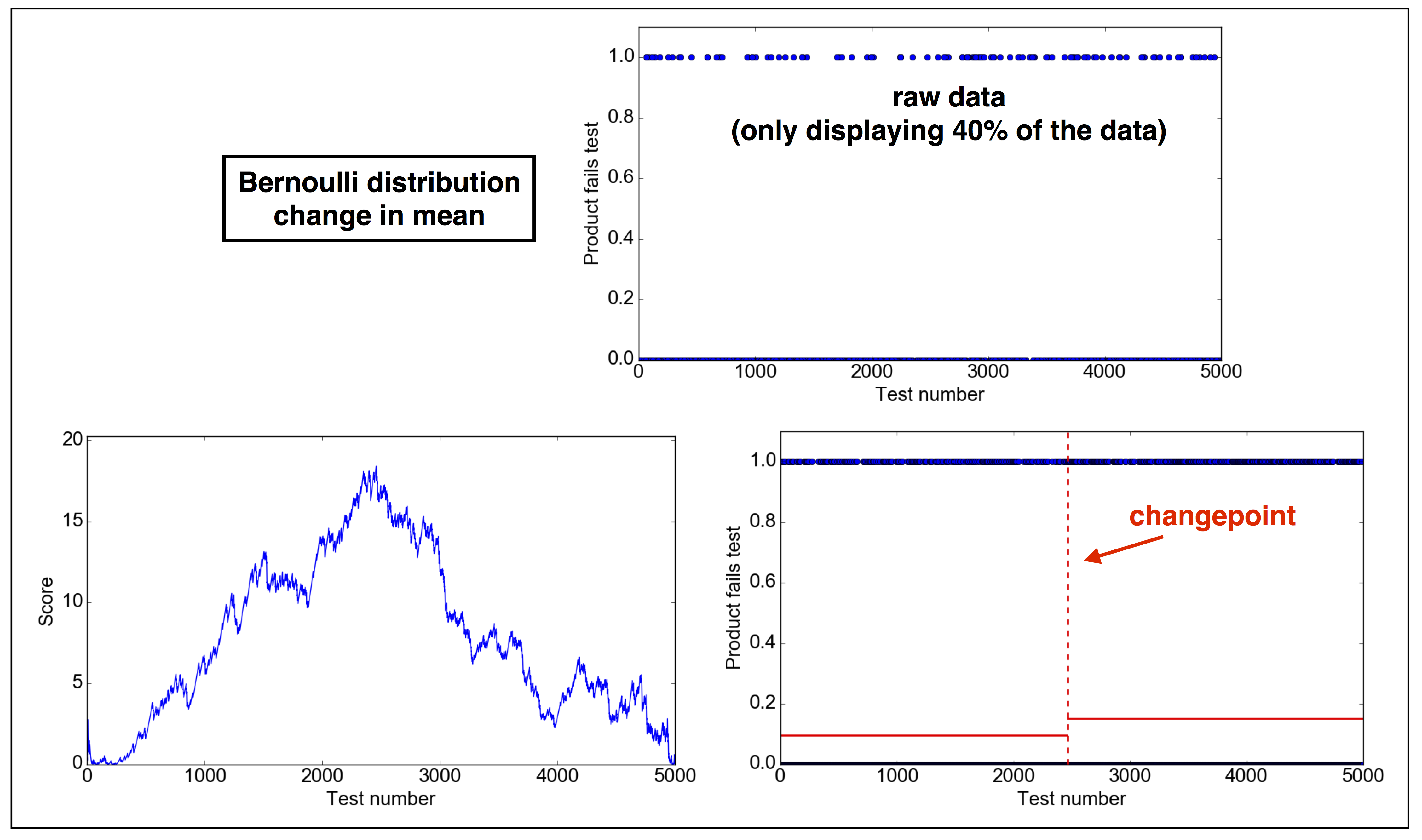
2.4 Problem 4. Poisson distribution: change in mean.
Problem definition: Under normal circumstances, a network system has a load of a few tens of hits per minute. Check whether there is a sudden change in the number of hits per minute in the data provided.
2.4.1 Parameters of problem 4
Note: these parameters are completely made up. You can change the parameters in the code as you wish, also making the test fail (not rejecting the null),
- Probability density distribution: $p(k)\sim \lambda^k\mathrm{e}^{-k}/k!$ where $k$ is the observed number of hits per minute and $\lambda$ is the expected number of hits per minute.
- $\lambda = 0.12 \ \ \mathrm{for} \ \ \tau\leq 2500; \lambda = 0.10 \ \ \mathrm{for} \ \ \tau>2500$
2.4.2 Solution
In IPython, run:1
2
3
4
5
6
7
8
9
10
11
12
13In [1]: run changepoint.py
In [2]: d = cpt(type="poisson-mean")
In [3]: d.plot_data()
In [4]: d.find_changepoint()
---------------------
2G = 4.716131e+02
sigma**2*lambda = 1.703439e+01
H0 rejected
Changepoint detected at position: 2497
m1 = 11.988787
m2 = 9.955653
---------------------
In [5]: d.plot_score()
⁂